
An introduction to GitOps
Recently I was thinking about how to orchestrate deployments across a set of Kubernetes clusters. The traditional recipe for this problem involves a traditional CI/CD tool, such as TeamCity or Jenkins, and some boilerplate scripts and tokens for authentication in order to access the cluster. A classic release pipeline defines how to service artifacts (such as Helm charts) are moved through each quality gate.
Additional infrastructure is necessary when the CI/CD tool is not supposed to run on your own premises but in the cloud itself. So called “federation clusters” are deployed to ensure that you have “something” which is always up and running, also checking for any changes in your repositories. When they detect a change, a new release is built and applied to the next environment in the pipeline. These pipelines usually look something like this:
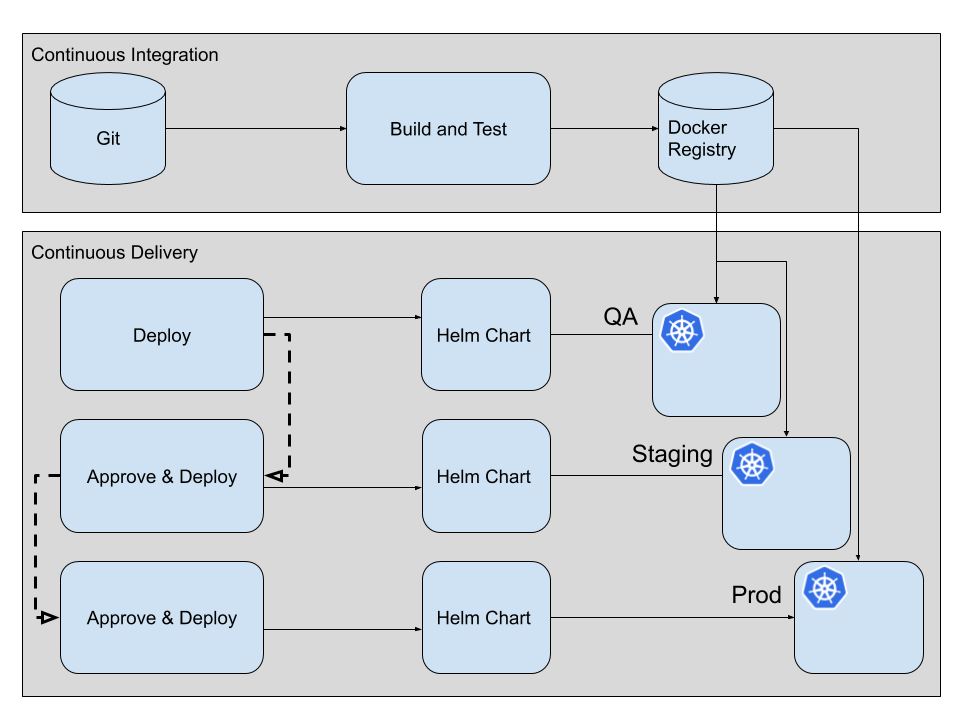
The problem with these tools is that they always access the cluster from outside. Hence, besides Git, there is a second source of truth (encoded in the pipeline itself), which defines how changes should be applied. it also requires the cluster being accessible from outside for these requests. And that usually means that sometimes the pipeline degrades to that:
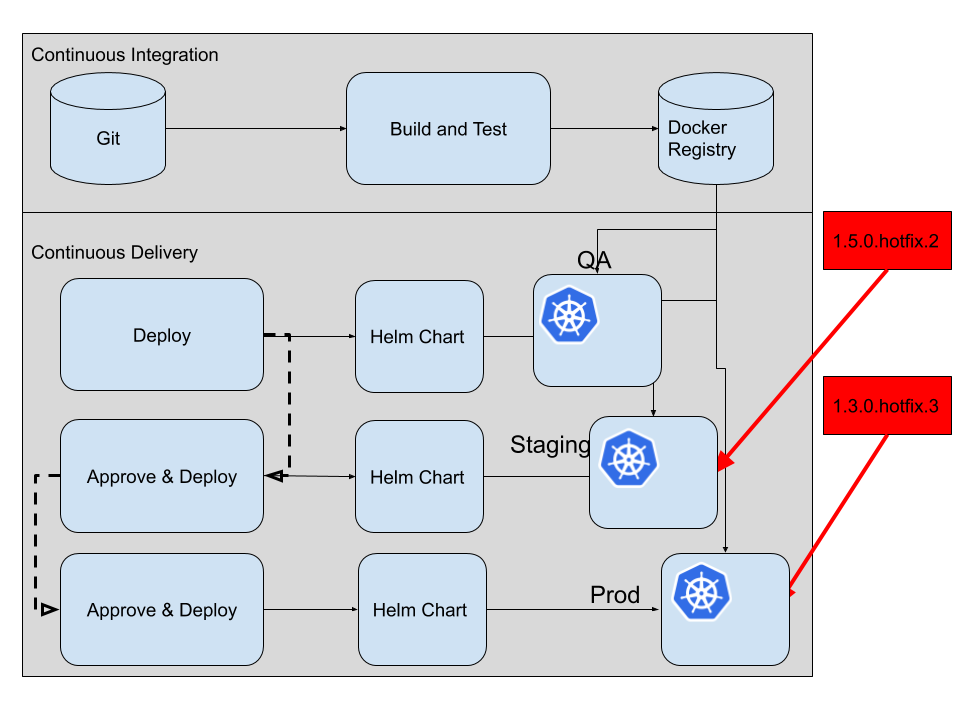
So even though your CI/CD build tool has a feature to trace down any deployment you did through the pipeline, it fails miserably when you allow compromising deployments to happen from outside. As these deployments become untraceable, also rolling back to the previous version comes with an additional risk of simply manually rolling out the previous version again, especially when your chose CI/CD tool doesn’t support rollbacks nicely.
GitOps
A new and recent paradigm is inverting the control for the pipeline. It is called “GitOps”, and refers to Git being the only source of truth regards to your deployments. A picture is more than thousands words, so there we go:
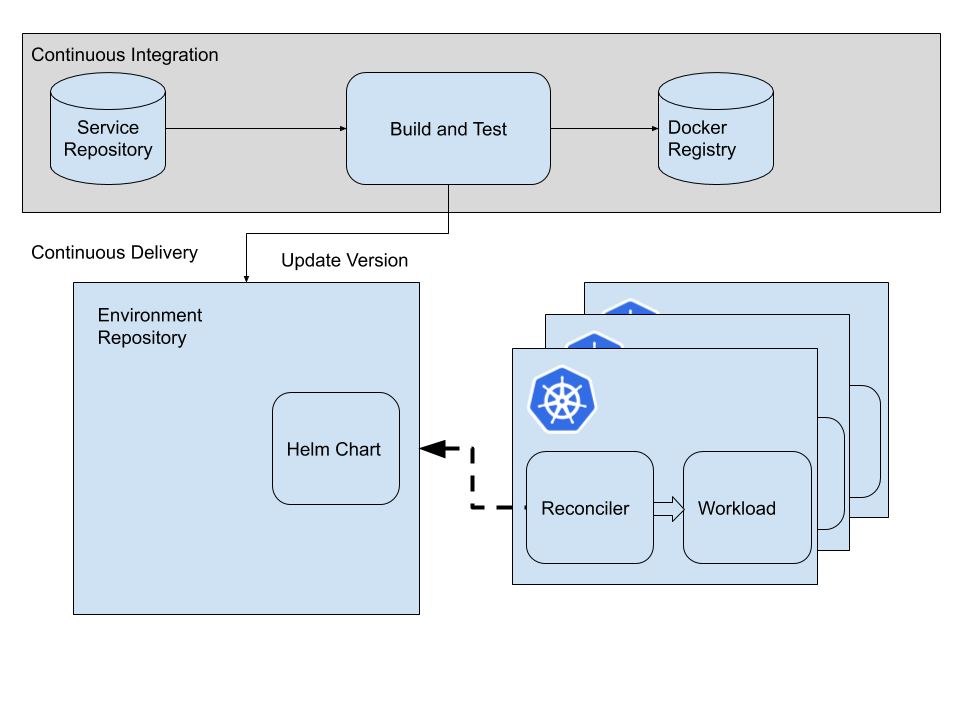
GitOps is based on the pull-principle, i.e pulling changes from the repository. A ‘reconciler’ - usually in form of a control-loop - observes declarative state in a Git repository and applies it onto your cluster from within. That means that the cluster is shielded away from external access but fetches its desired target state by itself and applies these changes automatically. During the CI stage, the version in the declarative definition is updated to point to the one desired.
Downsides
- Git is not designed for programmatic updates made by services, it is effectively mis-using it as a data store. Yes it can handle merge-conflicts, but it is all designed for human interaction in mind. This automated approach can also lead to unwanted API throttling as too much deployments are made throughout the day.
- Altough the commits made into Git are visible in its log, it takes substantial effort to analyse and parse these logs to answer questions about i.e. when a certain version was on which environment
- The more you try to avoid the mentioned issues in the first point, the more granular these repositories have to be. This might eventually result in one service repository per environment. If you have five environments and only ten services you can do the math on the number required. And I am not yet talking about maintaining them, i.e. keeping them aligned with policies and security measures.
- The declarative files are not entangled with Git. It doesn’t care about the structural correctness of them, so you have to provide additional effort to make sure only valid declarations enter the environment repositories.